Population Health Analytics
Assessing Race and Ethnicity Data Collection and Completeness with the ACG System





We continue our series on health disparities by discussing the collection of race and ethnicity data within the ACG System. Previously, we touched on measuring disease prevalence and health disparities by race and geography. Today, we’re sharing additional information on the importance of collecting this data, and how the unique features of the ACG System keep it all organized.
What is the Difference Between Race and Ethnicity?
Users of the ACG System have the option to input race and/or ethnicity to gain a deeper understanding of disparities impacting their populations. To take advantage of this new capability, it’s important for System users to understand race and ethnicity in their datasets.
While the terms race and ethnicity are often used together, there are differences. Race is a way to categorize people based on shared physical characteristics, like skin color. Ethnicity is used to group people based on shared cultural, traditional and familial bonds. When collecting race and ethnicity data, it is strongly preferred that the individuals reporting the data self-identify their racial and ethnic group. Most health agencies and care providers do ensure self-identification. However, it is important to trace data lineage and question the collectors of race and ethnicity data to ensure that this is the case.
How Are Race and Ethnicity Data Collected?
Collection of race and ethnicity data may be done within one variable or separated into two variables. For measurement purposes, the U.S. Government has determined a minimum set of five categories for race and two categories for ethnicity.
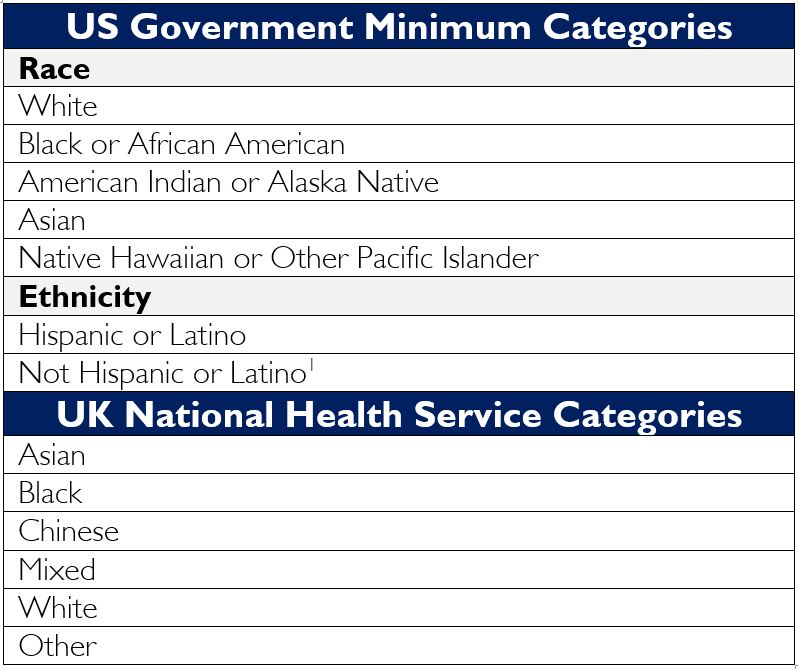
It’s important to note that states, counties, communities, health care organizations and other local entities may use variations or more granular categorizations.
Many reporting tools allow respondents to choose multiple values for race and ethnicity. When using the data for analytical purposes, it’s critical to understand if patients were allowed to select multiple values, and how multi-responses are tracked within the data. Likewise, the analyst should quantify the frequency of non-responses and understand how non-responses are handled. A best practice is to report a non-response rate, and calculate remaining percentages excluding non-responders.
These collection methods are not perfect and can result in gaps and missing data in some systems. Fortunately, the ACG System is robust enough to support the various ways in which race and ethnicity data are collected and is flexible enough to handle any type of internal categorization.
Obtaining Race and Ethnicity Data
As part of health plan enrollment, patients complete an intake form which usually contains questions related to race and ethnicity. These data are stored in files that track health plan enrollment and are a common source of race and ethnicity data. Health care providers are required to capture the race and ethnicity of patients in the EMR and may also have access to payer enrollment data. Self-insured employers may use enrollment data and supplement that information with human resources records.
Ensuring Completeness of Race and Ethnicity Data
Government agencies, public health departments, health plans and health care delivery organizations all collect race and ethnicity data. However the completeness of that data varies wildly from 0% to over 90%. Medicare typically has the highest completion rate with less than 5% unknown or unanswered, and commercial health plans have the lowest completion rate with anywhere from 19-100% missing data.
Race and ethnicity data completeness in Medicaid varies by state with about 40% of states having over 90% completion rates. An even higher percentage of users classify their race and ethnicity data as “high concern” or “unusable.” Since 2013, providers using EMR have collected standardized race and ethnicity data under CMS Meaningful Use requirements, yet completeness rates vary and there are concerns regarding whether patients are actually self-identifying.2
Five Steps to Determining Completeness of Race and Ethnicity Data
- Create a dataset of all unique individuals in the entire population of interest that contains a unique person identifier and race and ethnicity assignment
- Calculate the percent of the population with values that represent an actual race or ethnicity category
- Calculate the percent of the population with a missing value for race or ethnicity
- Calculate the percent of the population with a value for race or ethnicity that is unassignable such as “unknown” or “other”
- Analyze these three percentages and consider the use-case for the analysis
- Determine the best way to use race and ethnicity data:
- Include people with a meaningful race and ethnicity categorization in the analysis
- Include everyone in the analysis but assess those with missing, unknown, and actual race and ethnicity assignment separately
Identifying health disparities in a population first requires access to complete data. The ACG System properly segments race and ethnicity to provide a detailed geographical breakdown of a community. With the ACG System, your organization can understand where disparities happen and how to begin breaking down those barriers.
We still have much more information to share on this important topic! Follow along for our next blog post where we discuss some real-world examples of this data collection in action.
_________
1U.S. Department of Health and Human Services Office of Minority Health. (2021). “Explanation of Data Standards for Race, Ethnicity, Sex, Primary Language, and Disability”. https://minorityhealth.hhs.gov/omh/browse.aspx?lvl=3&lvlid=54
2James, C., Pamar, S., Scholle, S.H., Saynisch, P., Soucie, J. (2020). Improving Data on Race and Ethnicity: A Roadmap to Measure and Advance Health Equity. Grantmakers in Health, National Committee for Quality Assurance, The Commonwealth Fund. https://www.ncqa.org/wp-content/uploads/2022/01/GIH-Commonwealth-Fund-federal-data-report-part-2-1.pdf
Sign up for blog alerts and other insights from the ACG System team
Follow Us

