Articles
Johns Hopkins Research Finds BMI Data Improves Cost, Utilization Predictions
The latest paper to be published from the faculty at the Johns Hopkins Center for Population Health IT’s e-ACG System line of work – which focuses on bringing electronic health record data into the predictive modeling process – examines Body Mass Index information, showing its impact on PM and risk adjustment.

The researchers, all members of the Johns Hopkins ACG System R&D team – Hadi Kharrazi MD PhD, Hsien-Yen Chang PhD, Sara E. Heins PhD, Jonathan Weiner DrPH and Kim Gudzune MD — note in “Assessing the Impact of BMI Information on the Performance of Risk Adjustment Models in Predicting Healthcare Costs and Utilization” (published in Medical Care and featured in Predictive Modeling News November 2018) that “using electronic health records for population risk stratification has gained attention in recent years.”
- The reason: “Compared with insurance claims, EHRs offer novel data types — vital signs, for example — that can potentially improve population-based predictive models of cost and utilization.”
- Their findings: “EHR-extracted BMI levels can be used to enhance predictive models of utilization, especially if comprehensive diagnostic data are missing.”
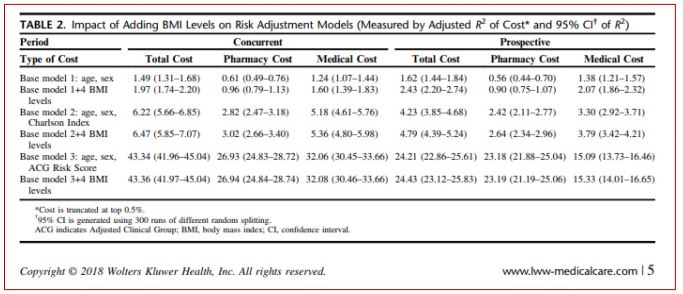
The Hopkins team used two years of claims and EHR data from an integrated health system, examining the addition of BMI to three diagnosis-based models of increasing comprehensiveness — demographics, Charlson and the Dx-PM model of the Adjusted Clinical Group system — to predict concurrent and prospective costs and utilization. Then they compared the performance of models with and without BMI.
- Among demographic models, R improvement ranged from 61% for prospective pharmacy costs to 29% for concurrent medical costs.
- Indeed, “BMI improvements to the prediction of all binary service-linked outcomes” — such as hospitalization, emergency department admission and being in the top 5% for total costs – ranged from 2% to 7%.
- Adding BMI to Charlson models “only improved total and medical cost predictions prospectively, by 13% and 15%, respectively, and improved predicting all prospective outcomes by 3% to 4%.”
- The researchers added: “No improvements in prediction were seen in the most comprehensive model.”
The paper is available here. Excerpts from the paper include:
- Recent epidemiologic studies show that total annual healthcare costs are 36% higher for individuals with obesity; medication costs are 68% higher, for example, hospitalizations are 34% higher and outpatient care is 26% higher.
- Those studies “have adjusted for basic demographic characteristics, socioeconomic status and health behaviors,” the paper adds, “but have avoided characteristics hypothesized to be on the causal pathway between BMI and costs, such as type 2 diabetes mellitus or coronary heart disease.”
- So they don’t “disentangle the costs attributable directly to obesity from indirect costs due to conditions associated with obesity.”
- The researchers note as well: “Payers use diagnosis-based predictive models to forecast costs and utilization, then profile providers, adjust payments and prioritize patients for care management interventions.” Therefore, understanding how BMI can enhance them is critical, so payers can focus on identifying high cost-risk patients.
- The limited role of BMI in Dx-based models “could be partly explained by obesity’s being coded as a diagnosis in the study population, especially within the higher classes of BMI, meaning BMI data’s added value was partially absorbed and consequently neutralized by the captured diagnostic codes of obesity.”
- But that happens less in lower BMI classes, the study points out, “indicating the need to further investigate the added value of BMI levels in improving utilization prediction among obese but under-coded subpopulations.”
- Also: “The usefulness of temporal patterns of BMI should be assessed as a risk marker for utilization, because the absolute BMI value does not show its trajectory, which could be predictive for certain outcomes of interest.”
Value-based care “has extended population health management efforts, including population analytics, from insurance to provider organizations,” the researchers conclude, noting that providers “often do not have access to the full spectrum of diagnostic codes accumulated in claims from all covered providers, so they use local EHR data for risk stratification.” But it’s “often limited to diagnostic codes collected within their network.” So adding BMI data “might represent a useful approach for providers to modestly improve their utilization predictions.”
Predictive Modeling News talked to Kharrazi, Weiner and Gudzune about making better use of BMI data.
Predictive Modeling News: How did you single out BMI for this particular comparison? Is there a progression of individual elements of the EHR that you’re following?
Hadi Kharrazi MD PhD, Jonathan Weiner DrPH & Kim Gudzune MD: At the Johns Hopkins Center for Population Health IT, we are undertaking a wide range of research exploring how “new” sources of data found in EHRs and other digital systems can expand our risk adjustment and predictive modeling tools beyond what is currently available in claims. BMI information is one such type of data. Moreover, it has been widely known for years that obesity is a very significant factor in understanding health outcomes and costs both at the individual and population levels. So obesity is a major topic of research for us at the Johns Hopkins Schools of Public Health and Medicine outside the context of this current paper as well.
PMN: Did the amounts and specific areas of improvement match your expectations? Were there any big surprises?
HK, JW & KG: This is one of the first scholarly papers that takes this type of methodological approach to document the impact of EHR-derived BMI on traditional RA and PM analyses that previously were based on more traditional claims-based diagnosis ICD risk factors. There had been some previous, more limited research suggesting that when comprehensive information is available — including all clinical diagnoses associated with obesity — improvements in model power might not be so high. That was more or less what we found. But for all models we evaluated — demographic only, a simpler Charlson Index using several diagnoses and a more comprehensive ACG score using all diagnoses — there was model improvement in all cases. The improvements in model performance had a greater proportional increase when the base model had less diagnostic information.
PMN: What can payers do with this information right now? What’s the main takeaway for readers?
HK, JW & KG: This paper — like our other recent studies your newsletter has featured — does show that new types of risk factors can be successfully extracted from EHRs and integrated into “traditional” PM and risk adjustment analyses. In addition to documenting the modest increase in model performance, we also offer a roadmap for how these new and important clinical data sources can and should be integrated into the population and care management data streams. The new data can then be used in a wide array of analytic efforts to improve care; and for sure understanding patterns of obesity will be critical to a wide range of these activities, both related to case finding and population stratification and beyond.
PMN: Any other comments?
HK, JW & KG: We at Johns Hopkins have a wide range of ongoing activities related to extracting new types of risk information from EHRs — e.g., BMI, lab, vital signs, clinician notes — and other new data sources to help shape the future of the population health analytics field. We are glad to share the methods and findings of our work with the field in peer-reviewed papers such as the one you are featuring here, so others can replicate our approaches if they wish. We also are hard at work implementing what we’ve learned into what we term the Johns Hopkins “e-ACG” initiative, so that these new sources of data can directly benefit the 175 million-plus patients cared for by organizations around the globe now using our Johns Hopkins ACG System analytic software.
Click here to read the paper “Assessing the Impact of BMI Information on the Performance of Risk Adjustment Models in Predicting Healthcare Costs and Utilization”.

